Containers are in the mainstream. They are no longer new and exotic. In a 2019 survey conducted by CNCF, 84% of respondents say they are using containers in production.
Kubernetes is increasingly becoming the preferred container orchestration tool that automates deployment, scaling and management of containerized applications.
This blog post summarizes the core concepts. This is intended to neither explain the concepts in detail nor do deep dives but to provide a quick reference for important concepts, especially for developers.
What are the benefits of running applications on Kubernetes?
- Service discovery – a mechanism that allows applications to find other applications and use the services they provide,
- Horizontal scaling – replicating your application to adjust to fluctuations in load,
- Load-balancing – distributing load across all the application replicas,
- Self-healing – keeping the system healthy by automatically restarting failed applications and moving them to healthy nodes after their nodes fail,
- Leader election – a mechanism that decides which instance of the application should be active while the others remain idle but ready to take over if the active instance fails.
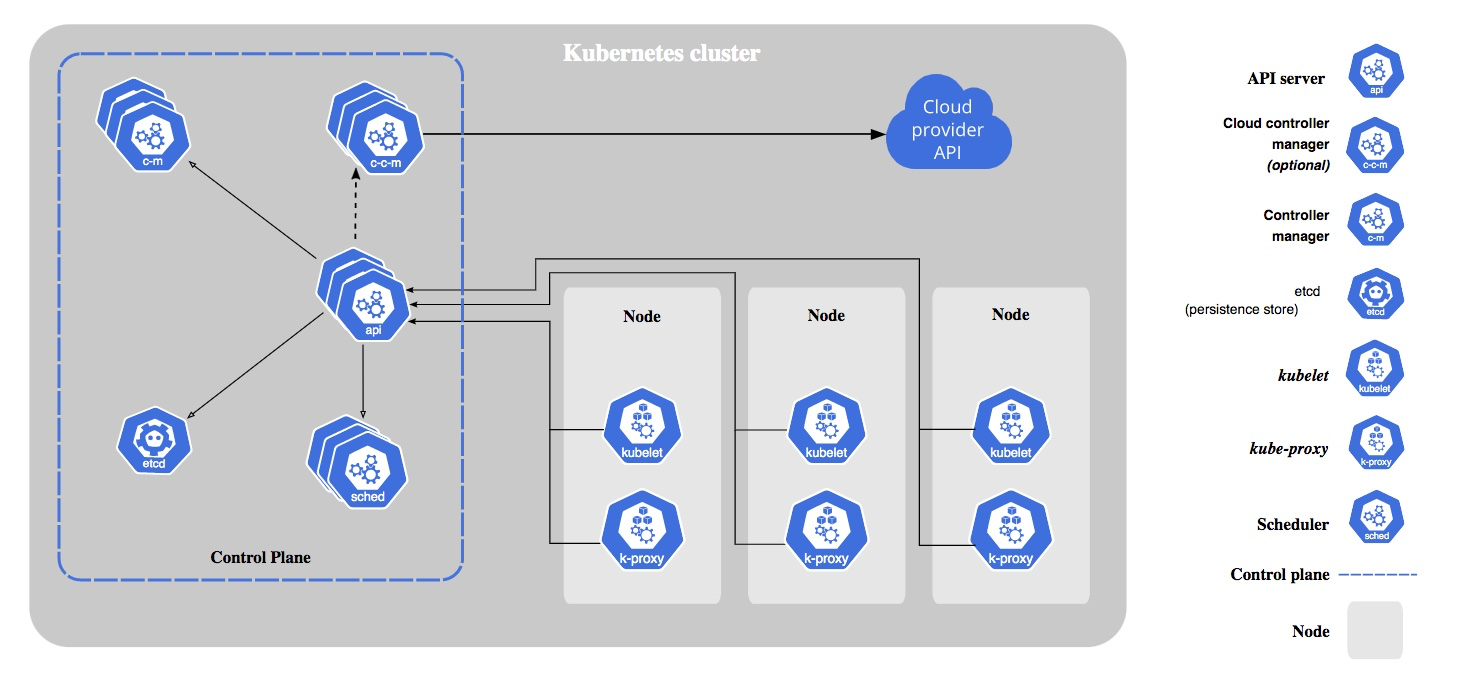
What are the components of Kubernetes?
Control plane:
- Kube-apiserver
- Etcd
- Kube-scheduler
- Kube-controller-manager
- Cloud-controller-manager
Node Components
- Kubelet
- Kube-proxy
- Container run time
What is the role of Kubernetes API?
Kubernetes API is used to deploy applications in the cluster. With the API, the entire cluster is treated as a single deployment surface, no matter how many servers are in the cluster. When an application is deployed in the cluster, Kubernetes chooses the best node.
What is a Pod?
Pod is a group of one or more containers and a specification on how to run them.
The containers that run in a pod share
- UTS namespace: same hostname
- Network namespace: same ip address, routing table and share the port space
- IPC Namespace: containers can communicate with each other using standard IPC communications like shared memory, message queueing, etc
What are the design patterns for multi-container pods?
- Sidecar pattern: Example Logging agent
- Adapter pattern: convert logs to common format
- Ambassador pattern: depends on the environment, database connections are established
What are the different phases of a pod?
- Pending: Till all containers are started
- Running: All containers have been created and at least one container is still running
- Succeeded: All containers have been terminated in success and will not be restarted
- Failed: All containers have been terminated and at least one of them terminated in failure
- Unknown: Pod status is unknown; Unable to communicate with Node on which the Pod is running
What are the different states of a container?
- Waiting
- Running
- Terminated
- Unknown
What is a container restart policy in Pod?
Restart policy tells kubelet what to do if containers in Pod are terminated. The allowed values are
- OnFailure: Container is restarted only if it exits with non-zero code
- Always: Container is restarted if it exits. Exit code doesn’t matter
- Never: Container is not restarted after it exits. Exit code doesn’t matter.
Note: Default value is Always.
How do you pass configuration data to applications running inside containers?
We can pass configuration to containers using
- Command line arguments: command and args in pod spec.
- Environment variables: setting env in pod spec.
- ConfigMap: Map containing key-value pairs to store non-sensitive configuration data
- Secrets: Map containing key-value pairs to store sensitive information like credentials, encryption keys, etc.
How do you access metadata of pods and other resources from applications running in containers?
- DownwardAPI : The pod’s own metadata
- Kubernetes API: To get metadata of other pods and resources. You can curl API server from the container
How would Kubernetes know if application is healthy?
A Probe is a diagnostic performed periodically by the kubelet on a Container. There are three different types of probes
- Liveness Probe: Checks whether the container is running.
- Startup Probe: Checks whether the application inside the container is started.
- Readiness Probe: Checks whether container is ready to respond to requests.
The probes are specified in pod definition spec.
How do you configure Probe?
Probes can configured using any of the three handlers
- ExecAction: Runs command in the container
- TCPSocketAction: Checks TCP on a port
- HTTPGetAction: Sends a HTTP GET request
What are Labels, Selectors and Annotations?
Labels and Selectors are used to group and / or filter objects
- Labels are attached to the objects ( tags)
- Selectors are used to filter the labeled objects
- Annotations are used to record other data for information purpose
What is a replicaSet?
ReplicaSet is a resource that ensures that a desired number of Pod replicas are always running. It uses a label selector to find the number of pods currently running.
We can scale out or scale in the application easily just by changing the desired number. To create new pods, it uses the template specified in the definition yaml file.
What is a Deployment?
Deployment is a high-level resource and a preferred method to deploy pods. Deployments brind the below capabilities.
- Self-healing: If pod fails, it will be replaced
- Scalability: we can scale pod replicas easily by changing the desired number
- Rolling updates: Zero downtime rolling updates to application
- Versioned Rollbacks: Rollback to previous deployment version
How does rolling update work?
Rollout process is triggered when a deployment is updated. It creates a new replica set for pods with a new image. The new replicaSet is scaled up slowly and at the same time the old replicaSet is scaled down gradually.
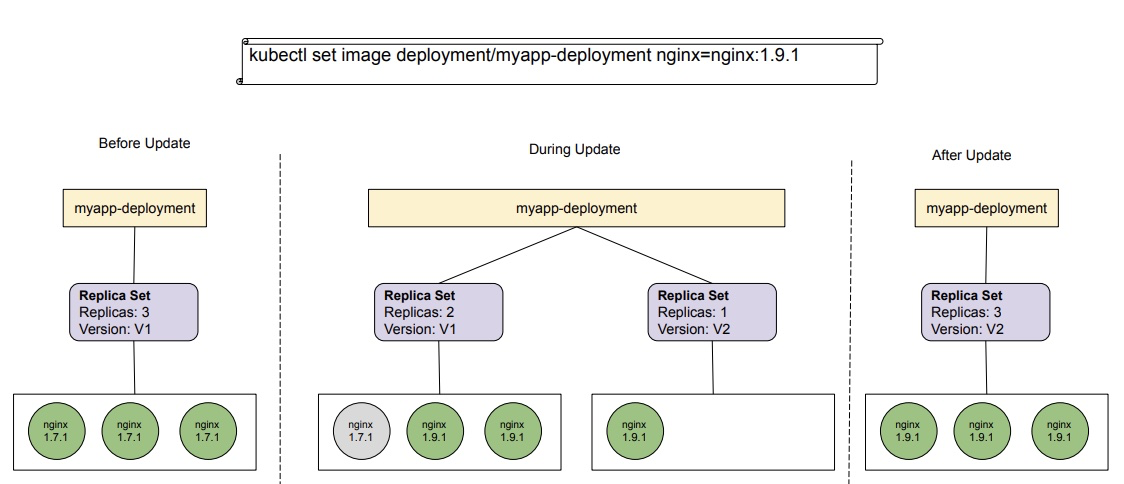
What is a reconciliation loop?
Kubernetes constantly checks if the current state of a resource matches the desired state if they don’t, the controller responsible for the resource calls API server to modify the resource, like add or delete pods.
What is a Service?
Service abstracts the application running on a set of pods. The member pods of a service are determined by selector.
As pods get replaced by deployments and replicaSets their ips keep changing, that makes communicating to them harder using their ips. Service frontends Pods with a stable Ip and also provides load balancing across the pods.
Every service defined in the cluster is assigned a DNS name. The A record for service is in this format: service.namespace.svc.cluster.local .
Notes
- Service is an object like pod, replicaSet and deployment
- Every service would get a stable port, stable Ip and stable DNS
- As the pods come-and-go, the Service dynamically updates the list of healthy pods.Service leverages labels to dynamically select the pods
What are the different types of services supported by Kubernetes?
- Cluster IP; Accessible inside the cluster
- NodePort; Accessible from outside the cluster
- LoadBalancer; Integrates with load balancers from cloud provider and allows clients to reach from internet
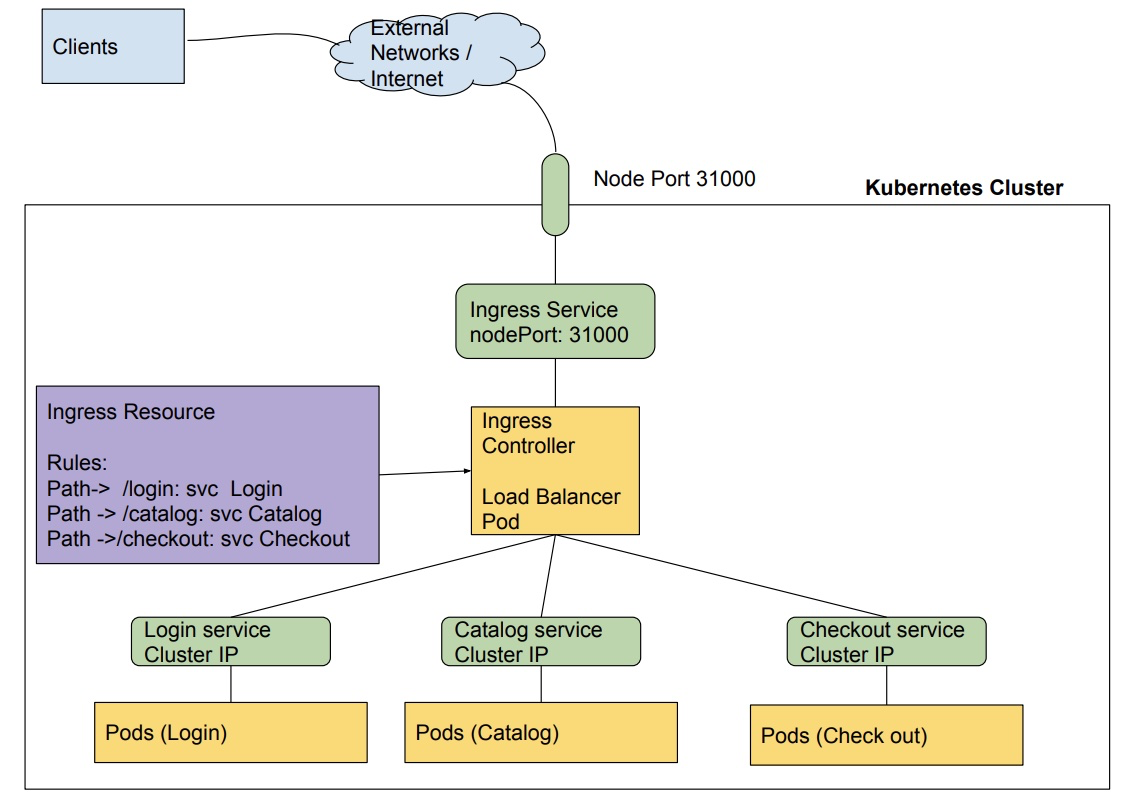
- Ingress Controller: A pod built using reverse proxies that can distribute load to multiple services as determined by ingress resources.
What is Cluster IP Service?
Cluster IP Service is accessible internally in the cluster and it has stable IP and port. Requests to a service are load balanced across all pods that are members of the service.
What is NodePort Service?
Exposes the Service on each Node’s IP at a static port (the NodePort). A ClusterIP Service, to which the NodePort Service routes, is automatically created. You’ll be able to contact the NodePort Service, from outside the cluster, by requesting NodeIP:NodePort.
What is LoadBalancer Service?
Exposes the Service externally using a cloud provider’s load balancer. NodePort and ClusterIP Services, to which the external load balancer routes, are automatically created.
What is an Ingress Controller?
Ingress Controller is simply a pod that interprets ingress rules. It is a layer 7 load balancer.
The rules for the controller are specified in ingress resources.
What are namespaces?
Kubernetes provides a way to create multiple virtual clusters within a physical cluster. The virtual clusters are called namespaces.
Use cases:
- Teams: If multiple teams are deploying resources on a shared Kubernetes cluster, we can create a namespace for each team and have the team manage the namespace.
- Environments: If a cluster is shared among resources belong to multiple environments , like Production, Development, etc, we can create a namespace for each environment
Features
- Address space: Namespace partition the address space below the cluster domain. Services deployed in “prod” namespace and “dev” namespace will be in format “service-name.prod.svc.cluster.local” and “service-name.dev.svc.cluster.local” respectively.
- Cluster resources: Resources of a cluster can be divided among namespaces by using resourceQuota.
Note: By default, all the resources are deployed in “default” namespace.
How can we improve container security?
Security related configurations can be applied using SecurityContext.
SecurityContext defines the set of security settings , like uid, gid, SELinux role etc, that can be applied on containers. These are specified in pod spec.
SecurityContext can be applied at pod level or at container level. The settings defined at pod level are applied to all the containers in the pod. Container level settings override pod level settings.
How can the communication between pods be secured?
Network policies control the traffic between pods and network endpoints. The policies are applied on pods. They are associated with pods using labels and selectors.
By default, Kubernetes “All Allow” ; it allows communication from a pod to any other pod within the cluster.
Network plugins implement the policies. All plugins don’t support network policies.
What are Kubernetes volumes?
A volume is a directory which is accessible to all of the containers in a Pod. Kubernetes supports different types of volumes. Some of them are listed below
- awsElasticBlockStore: Mounts AWS EBS Volume
- azureDisk: Mounts Azure Data Disk
- cinder: Mounts Openstack Cinder Volume
- emptyDir: mounts the medium backed by node
- gcePersistentDisk: mounts GCE persistent disk
- hostPath: Mounts a file or directory from node’s file system
- iscsi: mount iscsi volume
- nfs: mount nfs volume
- persistentVolumeClaim: A way to use a pre- or dynamically provisioned persistent storage
- configMap: Injects configuration data into pods
- Secret: Mount the secrets as files
- downwardAPI: Allows containers to know about the pods itself.
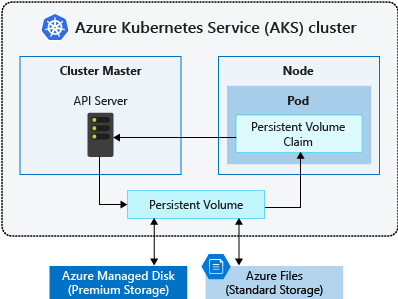
What are Persistent Volumes?
A persistent volume (PV) is a storage resource created and managed by the Kubernetes API that can exist beyond the lifetime of an individual pod.
Persistent volume abstracts the underlying storage technology.
Pods consume storage from Persistent Volume(PV) through Persistent Volume Claim. In the Persistent Volume Claim (PVC), developers specify size, storage class and PV selector. There is 1:1 relationship between PVC and PV
What is downwardAPI Volume?
It is sometimes useful for a container to have information about itself, but we want to be careful not to over-couple containers to Kubernetes. The downward API allows containers to consume information about themselves or the system and expose that information how they want it, without necessarily coupling to the Kubernetes client or REST API.
How can we use ConfigMap to configure containers?
- Inside a container command and args.
- Environment variables for a container.
- Add a file in read-only volume, for the application to read.
- The application code inside the Pod uses the Kubernetes API to read a ConfigMap.
How can applications running inside containers in a cluster talk to the cluster?
Service account: Applications like Promotheus, Jenkins etch that are running in the cluster can interact with Kubernetes Cluster using service account
How do you define application requirements?
By default, each container gets 0.5 cpu and 256Mb ram. This can be modified by specifying request and limit in pod spec.
- Request: minimum resources container gets when started
- Limit: Maximum resources container can use
How does the Kubernetes scheduler work?
Kubernetes scheduler is responsible for assigning a node to pods to run on.
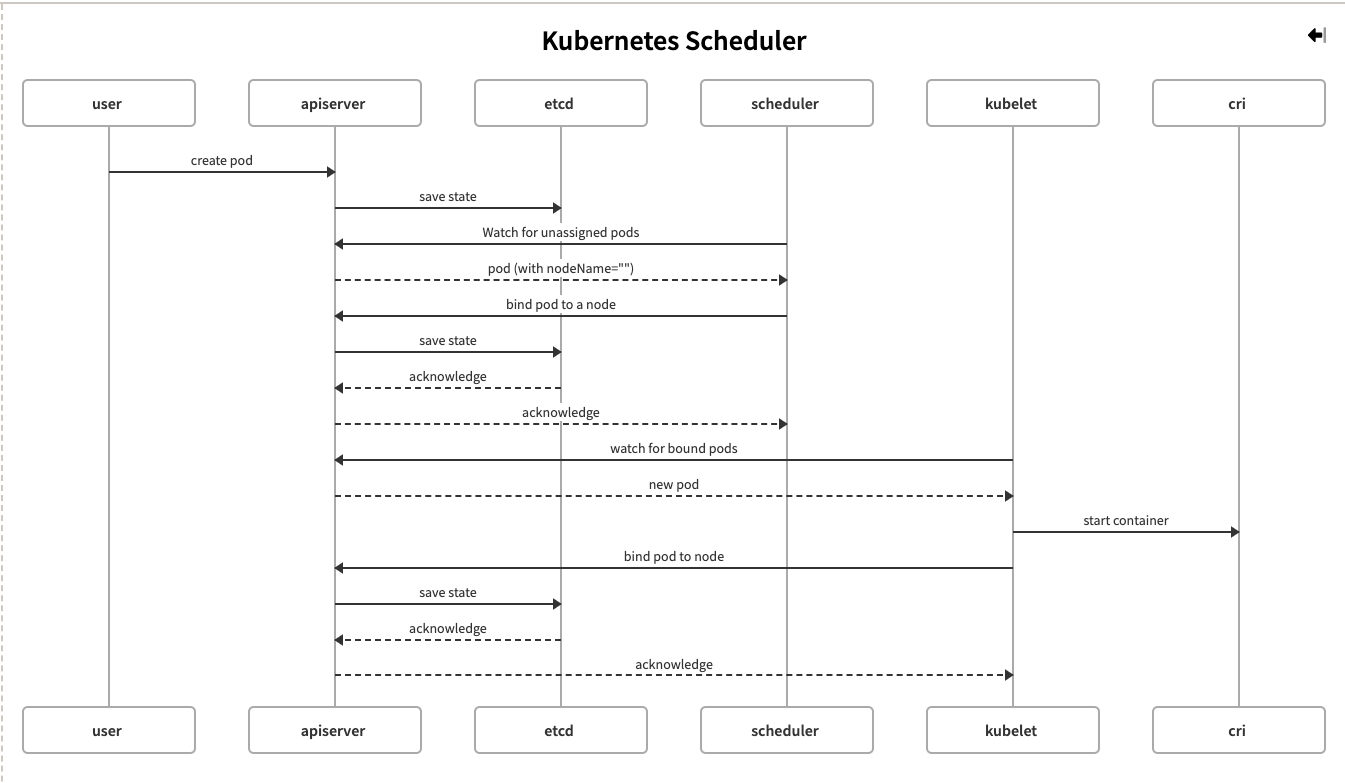
Image source: https://harshanarayana.dev/2020/06/writing-a-custom-kubernets-scheduler/ .
The default scheduler is Kube-scheduler. Kube-scheduler selects a node for the pod in a 2-step operation:
- Filtering: Finds the list of nodes that meet resource requirements for pod
- Scoring: Selects the best node among them
How do you influence which node is selected for running a pod?
- Node Selectors: Assign labels to nodes and specify the label in pod spec (nodeSelector)
- Affinity rules. Assign labels to nodes and specify Node-Affinity / Node-Anti Affinity rules
- Taints and Tolerations: Adding taints on nodes we can reject deployment of certain pods. Tainted nodes allow only the pods that have tolerations to the taints.
What are Node Selectors?
nodeSelector is the simplest recommended form of node selection constraint. nodeSelector is a field of PodSpec. It specifies a map of key-value pairs. For the pod to be eligible to run on a node, the node must have each of the indicated key-value pairs as labels
What are Node Affinity rules?
Node affinity is specified as field nodeAffinity of field affinity in the PodSpec.
Types of node affinity
- requiredDuringSchedulingIgnoredDuringExecution
- preferredDuringSchedulingIgnoredDuringExecution
- requiredDuringSchedulingRequiredDuringExecution
What are Taints and Tolerations?
Node affinity, is a property of Pods that attracts them to a set of nodes (either as a preference or a hard requirement). Taints are the opposite — they allow a node to repel a set of pods.
Tolerations are applied to pods, and allow (but do not require) the pods to schedule onto nodes with matching taints.
What is a Horizontal Pod Autoscaler?
The Horizontal Pod Autoscaler automatically scales the number of Pods in a replication controller, deployment, replica set or stateful set based on observed CPU utilization
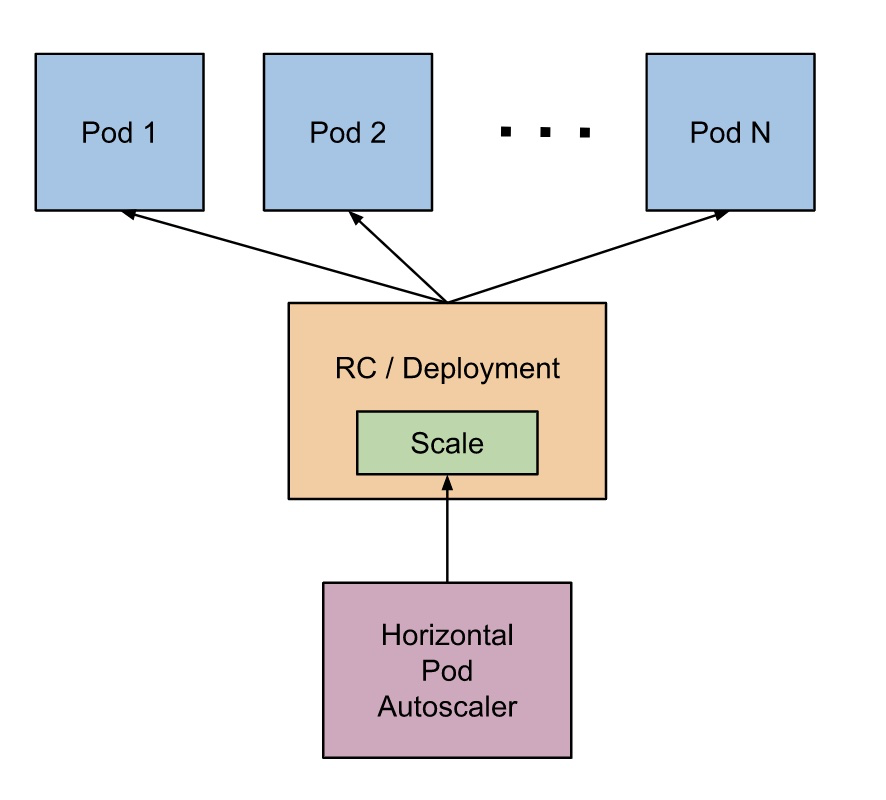
How do you monitor nodes and pods?
How do you store logs from pods?
Container logs are only available as long as it is running. Once the container is deleted the application logs also get deleted. Kubernetes does not provide centralized logging.
However, we can push the application logs to the central logging server by using logging tools like ELK.
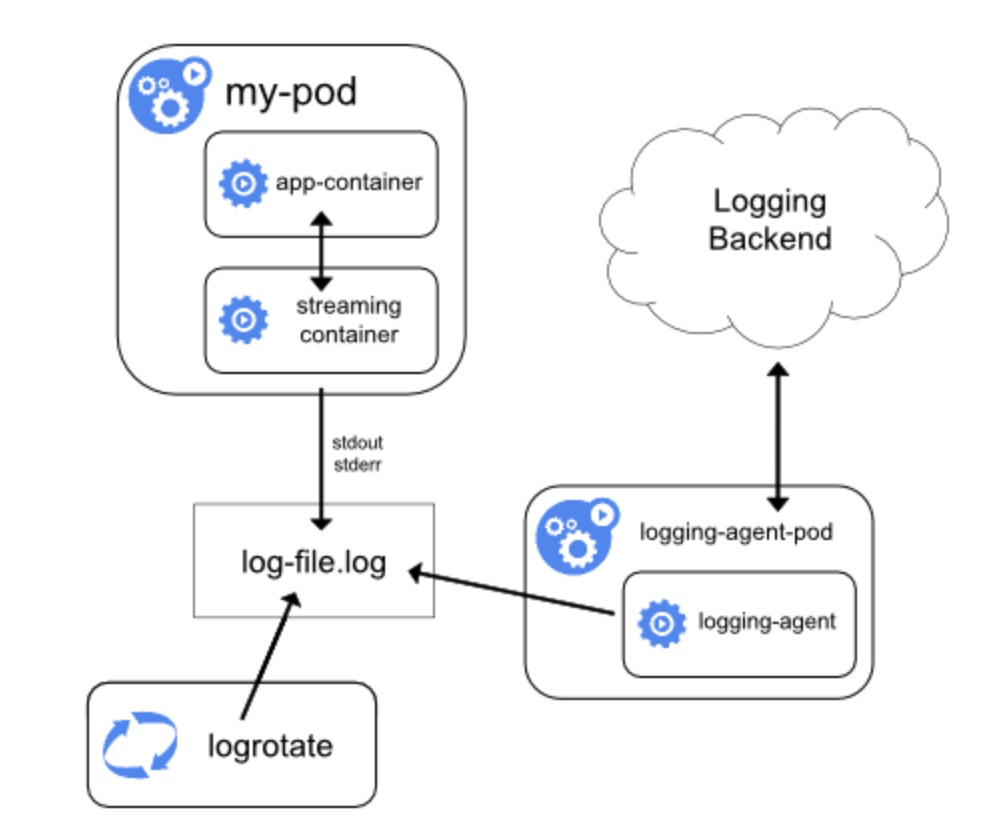
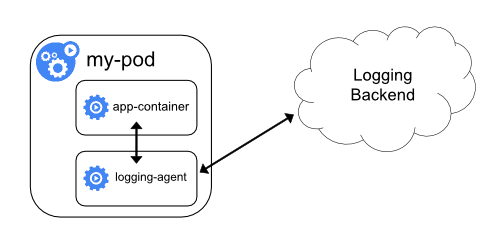
How do you run batch jobs in Kubernetes?
- Jobs using one Pod that runs once
- Parallel Jobs with a fixed completion count
- Parallel Jobs with a work queue
References
Video Courses
- Kubernetes Certified Application Developer (CKAD) with Tests by Mumshad Mannambeth
Bibliography
- Kubernetes in Action by Marko Luksa
- The Kubernetes book by Nigel Poulton
Websites and blogs
- Kubernetes.io
- StackOverflow
- Many other countless sites
