The number of tools in Devops ecosystem is growing fast everyday. Yet, Terraform remains the most important one.
This blog would act as a quick reference on Terraform and Atlantis. It assumes the reader has some experience / knowledge on terraform.
Q) How do you set up Terraform on your local machine?
- Install AWS CLI
- Setup aws credentials.
- Set environment variables. AWS_ACCESS_KEY_ID & AWS_SECRET_ACCESS_KEY
- Or run aws configure
- Install Terraform Installation of terraform is very simple and easy. You can use any popular package manager to install it, you can follow the link below Reference: https://learn.hashicorp.com/tutorials/terraform/install-cli.
Q) What are the most used Terraform commands?
- terraform init : terraform scans the code and
- Downloads modules
- Downloads the plugins for providers to .terraform folder.
- Configures backend to store tfstate file
- terraform plan: shows what terraform will do before actual changes
- terraform apply: changes the infrastructure (adds, deletes & modifies resources)
- terraform destroy: destroys the infrastructure
Q) What are providers?
Terraform relies on plugins called “providers” to interact with remote systems. Terraform configurations must declare which providers they require, so that Terraform can install and use them
Terraform 0.13 and later:
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 3.0"
}
}
}
# Configure the AWS Provider
provider "aws" {
region = "us-east-1"
}
# Create a VPC
resource "aws_vpc" "example" {
cidr_block = "10.0.0.0/16"
}
Terraform 0.12 and earlier:
# Configure the AWS Provider
provider "aws" {
version = "~> 3.0"
region = "us-east-1"
}
# Create a VPC
resource "aws_vpc" "example" {
cidr_block = "10.0.0.0/16"
}
Q) How do you deploy resources across multiple regions in AWS?
Configure multiple providers
# The default provider configuration; resources that begin with `aws_` will use
# it as the default, and it can be referenced as `aws`.
provider "aws" {
region = "us-east-1"
}
# Additional provider configuration for west coast region; resources can
# reference this as `aws.west`.
provider "aws" {
alias = "west"
region = "us-west-2"
}
Specify provider at resource or module level
resource "aws_instance" "foo" {
provider = aws.west
# ...
}
module "aws_vpc" {
source = "./aws_vpc"
providers = {
aws = aws.west
}
}
Q) List me more terraform commands that are used in development?
- terraform output
- terraform state
- terraform import
Q) What files are excluded from version control / go into .gitignore?
- .terraform
- .tfstate
- .tfstate.backup
Q) How do you define input variables?
Input variables Each input variable must be declared using a variable block.
variable "image_id_1"{
type = string
description = "The id of the machine image (AMI) to use for the server."
default = "ami-xyz"
}
variable "image_id_2" {
type = string
default = "ami-xyz"
}
variable "image_id_3" {
type = string
}
variable "image_id_4"{}
Note
- Type specifies what value types are accepted. If type is not present, it accepts any value
- If default argument is present, the default value will be used if no value is set while calling the terraform module
How do you pass values to variables?
#1. -var option
terraform apply -var="image_id=ami-abc123"
#2. -var-file
terraform apply -var-file="testing.tfvars"
#3 Setting environment variables
export TF_VAR_image_id=ami-abc123
Q) What are terraform supported types?
- String
- Number
- Bool
- List
- Map
- Set
- Object
- Touple
- Any (default)
Q) What are type constraints?
- list(number), list(string)
- map(string)
Q) What is string interpolation?
Q) What are lifecycle settings?
- create_before_destroy: creates new resource before deleting the existing resource
- prevent_destroy: Any attempt to destroy the resource will cause terraform to error out and exit
Q) How do you add a lifecycle setting to resources?
lifecycle{
create_before_destroy = true
}
Q) What is data_source resource?
It queries the provider for data and the data is available for other resources to refer.
It can also query terraform_remote_state (.tfstate)
Q) What is terraform state?
.tfstate file contains a mapping of real resources to the ones specified in code.
Q) Where do you store state files?
Supported backends
- S3
- Azure Storage
- Google Cloud Storage
- Terraform Cloud
- Terraform Enterprise
terraform {
backend "s3" {
# bucket = ""
# key = "/terraform.tfstate"
# region = "us-east-2"
# dynamodb_table = ""
# encrypt = true
}
}
Q) How do you lock tfstate using dynamodb?
- Create a Dynamodb table for storing locks. The table must have a primary key named LockID with type of string. If not configured, state locking will be disabled.
- Specify table in terraform backend “s3” block
The value of LockID is made up of
Q) Why should state files not be stored in version control?
- Locking: No locking mechanism available
- Secrets: All data in tf state file is stored in plain text
Q) Can we parameterize the backend resource? Does it allow variables?
Q) What are terraform workspaces?
Workspaces allow you to store terraform state in multiple, separate, named workspaces
- terraform workspace new wspace1: creates new workspace wspace1
- terraform workspace list
- terraform workspace select wspace1
- terraform workspace shows; shows selected workspace
Q) How does the .tfstate path change when workspaces are used?
S3 bucket: env:/{workspace name}/{keypath specified in backend}
Q) How do you change instance type based on the workspace?
instance_type = terraform.workspace == “default” ? “t2.medium” : “t2.micro” |
Q) How do you query remote .tfstate?
data "terraform_remote_state" "db"{
backend = "s3"
config = {
bucket = "mybucket01"
key = "stage/mydb/terraform.tfstate"
region = "us-east-1"
}
}
Q) What is a terraform module?
A folder containing terraform configuration files is called a module.
The concept of modules allows us to break large code bases into small manageable chunks. It enables code reuse.
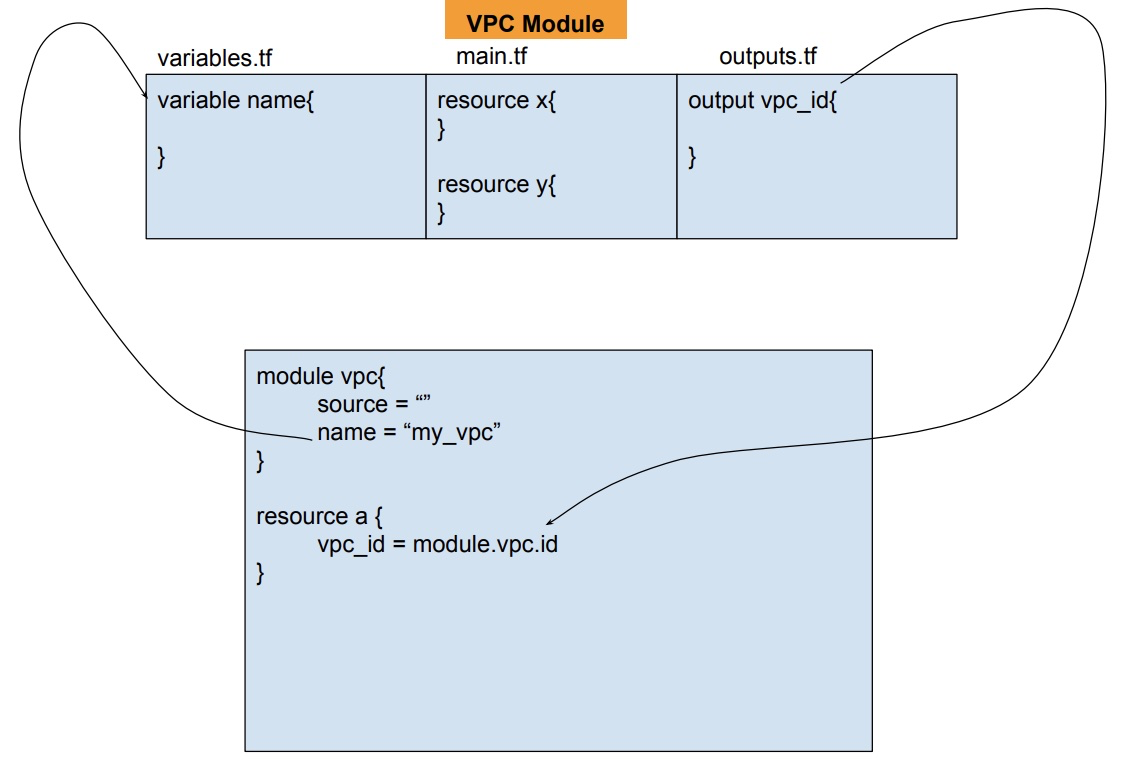
Q) How do you pass inputs to module and consume its outputs
Q)What are locals?
Locals are temporary variables. Their scope is within the module.
They are helpful to avoid repeating the same values or expressions multiple times in a configuration
A set of related local values can be declared together in a single locals block:
locals {
service_name = "forum"
owner = "Community Team"
}
locals {
# Ids for multiple sets of EC2 instances, merged together
instance_ids = concat(aws_instance.blue.*.id, aws_instance.green.*.id)
}
locals {
# Common tags to be assigned to all resources
common_tags = {
Service = local.service_name
Owner = local.owner
}
}
Q) How do you iterate or create loops in terraform?
The below constructs can be used
- Count: To create multiple resources
- For_each
- For
Q) How do you do conditionals in terraform?
- Count
- Combination of for_each and for
- If string directive
Q) What is the use of a count parameter?
The count parameter on a resource defines how many copies of the resource to create.
Example 1:
resource "aws_instance" "web" {
instance_type = "t2.small"
ami = data.aws_ami.ubuntu.id
# This will create 4 instances
count = 4
}
Example 2: use count.index
variable "user_names" {
type = list(string)
default = ["alpha", "beta", "gamma"]
}
resource "aws_iam_user" "seteam" {
count = length(var.user_names)
name = var.user_names[count.index]
}
Example 3: set count using ternary syntax
variable "environment" {
type = "string"
default = "Dev"
}
resource "aws_instance" "web" {
instance_type = "t2.small"
ami = data.aws_ami.ubuntu.id
# This will create 4 instances
count = "${var.environment == "Prod" ? 4 : 2}"
}
Q) How do you use for_each expression?
The for_each expression is used to
1) create multiple copies of a resource
2) create multiple copies of an inline block within a resource
Example 1: create multiple copies of a resource
variable "user_names" {
type = list(string)
default = ["alpha", "beta", "gamma"]
}
resource "aws_iam_user" "seteam" {
#for_each supports sets and maps only
for_each = toset(var.user_names)
name = each.value
}
Example 2: create multiple inline blocks in a resource
variable "common_tags" {
type = map(string)
default = {
"maintained_by" = "SE Team"
"cost_center" = "c1001"
}
}
resource "aws_autoscaling_group" "example" {
launch_configuration = aws_launch_configuration.example.id
availability_zones = data.aws_availability_zones.all.names
min_size = 2
max_size = 2
# Use for_each to loop over var.common_tags
dynamic "tag" {
for_each = var.common_tags
content {
key = tag.key
value = tag.value
propagate_at_launch = true
}
}
}
Q) How do you use a for expression?
For expression is used
- To generate a single value. It is similar to list comprehension / dictionary comprehension in python.
- To loop in string directive
Example 1:
variable "user_names" {
type = list(string)
default = ["alpha", "beta", "gamma"]
}
output "upper_user_names" {
value = [for name in var.user_names: upper(name)]
}
Example 2:
variable "user_names" {
type = map(string)
default = {
alpha = "Engineer"
beta = "Sr.Engineer"
gamma = "Manager"
}
}
output "roles" {
value = { for name, role in var.user_names:
name => role
}
}
Example 3: for in string directive
variable "user_names" {
type = list(string)
default = ["alpha", "beta", "gamma"]
}
output "string_directive_example" {
value = <for name in var.user_names}
${name}
%{ endfor }
EOF
}
Q) How do you combine for_each and for to create conditionals?
The number of resources or inline blocks created by for_each expression depends on the collection passed to it. If you pass an empty collection, it creates 0 resources or 0 inline blocks. If you pass an non-empty collection, it creates 1 or more resources or inline blocks.
dynamic "tag"{
for_each = {
for key, value in var.custom_tags:
key => upper(value)
if key != "Name"
}
content {
key = tag.key
value = tag.value
}
}
Q) What are string directives?
variable "environment" {
type = string
default = "dev"
}
output "string_directive_example" {
value = "Hello, %{ if var.environment == "prod"}
${environment}
%{ endif }"
}
Q) What are provisioners and types of provisioners available?
Provisioners are used to execute scripts on a local or remote machine as part of resource creation or destruction. Provisioners can be used to bootstrap a resource, cleanup before destroy, run configuration management, etc.
Terraform supports different type of provisioners
- file: copies files or directories from the machine executing Terraform to the newly created resource
- local-exec: invokes a local executable, on the machine running Terraform, after a resource is created
- remote-exec: invokes a script on a remote resource after it is created
Q) How do you specify provisioners?
By adding a provisioner block inside the resource block of a compute instance
resource "aws_instance" "web01" {
# ...
# Copies the myapp.conf file to /etc/myapp.conf
provisioner "file" {
source = "conf/myapp.conf"
destination = "/etc/myapp.conf"
}
}
resource "aws_instance" "web02" {
# ...
provisioner "local-exec" {
command = "echo ${aws_instance.web.private_ip} >> private_ips.txt"
}
}
resource "aws_instance" "web03" {
# ...
provisioner "remote-exec" {
inline = [
"puppet apply",
"consul join ${aws_instance.web.private_ip}",
]
}
}
Q) What is a null_resource?
The null_resource resource implements the standard resource lifecycle but takes no further action. The primary use-case for the null resource is as a do-nothing container for arbitrary actions taken by a provisioner
resource "aws_instance" "cluster" {
count = 3
# ...
}
resource "null_resource" "cluster" {
# Changes to any instance of the cluster requires re-provisioning
triggers = {
cluster_instance_ids = "${join(",", aws_instance.cluster.*.id)}"
}
# Bootstrap script can run on any instance of the cluster
# So we just choose the first in this case
connection {
host = "${element(aws_instance.cluster.*.public_ip, 0)}"
}
provisioner "remote-exec" {
# Bootstrap script called with private_ip of each node in the cluster
inline = [
"bootstrap-cluster.sh ${join(" ", aws_instance.cluster.*.private_ip) }",
]
}
}
Q) How do you store secrets for resources provisioned by Terraform, example db passwords?
There are many ways to store secrets, but the best way is to store them in dedicated secret stores like Hashicorp Vault, AWS Secrets Manager, etc
- Environment Variables: Declare a variable for password in terraform code and set TF_VAR environment variable before executing plan / apply commands
- Encrypted secrets in code: Encrypt secrets using KMS and supply them to aws_kms_secrets data source.
- No Encrypted secrets in code: Store encrypted secrets in secret managers like AWS secrets manger, Hashicorp vault, etc and provide the name of the secret to code.
Example that shows encrypted secrets in code
data "aws_kms_secrets" "example" {
secret {
# ... potentially other configuration ...
name = "master_password"
payload = "AQECAHgaPa0J8WadplGCqqVAr4HNvDaFSQ+NaiwIBhmm6qDSFwAAAGIwYAYJKoZIhvcNAQcGoFMwUQIBADBMBgkqhkiG9w0BBwEwHgYJYIZIAWUDBAEuMBEEDI+LoLdvYv8l41OhAAIBEIAfx49FFJCLeYrkfMfAw6XlnxP23MmDBdqP8dPp28OoAQ=="
context = {
foo = "bar"
}
}
secret {
# ... potentially other configuration ...
name = "master_username"
payload = "AQECAHgaPa0J8WadplGCqqVAr4HNvDaFSQ+NaiwIBhmm6qDSFwAAAGIwYAYJKoZIhvcNAQcGoFMwUQIBADBMBgkqhkiG9w0BBwEwHgYJYIZIAWUDBAEuMBEEDI+LoLdvYv8l41OhAAIBEIAfx49FFJCLeYrkfMfAw6XlnxP23MmDBdqP8dPp28OoAQ=="
}
}
resource "aws_rds_cluster" "example" {
# ... other configuration ...
master_password = data.aws_kms_secrets.example.plaintext["master_password"]
master_username = data.aws_kms_secrets.example.plaintext["master_username"]
}
Example that shows using AWS secrets manager
#Get secret metadata
data "aws_secretsmanager_secret" "master_password" {
name = "${var.master_password_secret_name}"
}
Get secret data
data "aws_secretsmanager_secret_version" "master_password" {
secret_id = data.aws_secretsmanager_secret.master_password.id
}
Q) What are the different ways of bootstrapping ec2 instances provisioned through terraform?
- User_data
- Remote_exec provisioner
Q)How do you pass commands to user_data?
- Embedded into tf file using heredoc syntax ( <
- String interpolation syntax to read content from file
- Template file
# Example1: heredoc syntax
resource "aws_instance" "web01" {
# ...
user_data = <<-EOF
#!/bin/bash
puppet apply
EOF
}
# Example2: String interpolation
resource "aws_instance" "web02" {
# ...
user_data = "${file("bootstrap_puppet.sh")}"
}
# Example3: Templates
data "template_file" "init" {
template = "${file("init.tpl")}"
vars = {
consul_address = "${aws_instance.consul.private_ip}"
}
}
resource "aws_instance" "web03" {
# ...
user_data = "${data.template_file.init.rendered}"
}
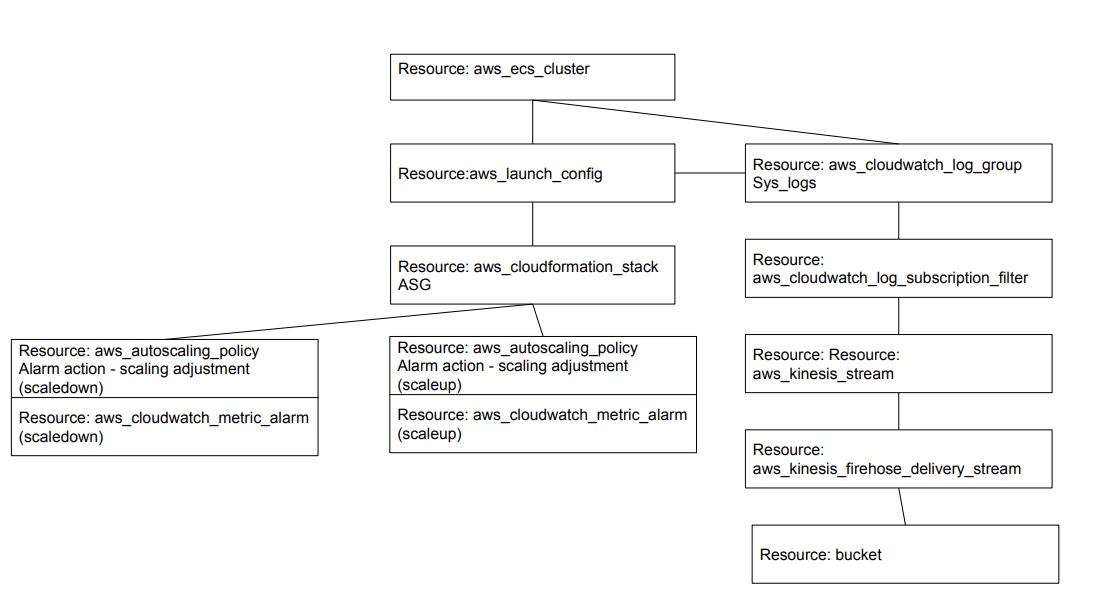
Q) How do you structure code repo for creating ECS cluster?
Resources created:
/env
cluster-app01-dev.tfvars
cluster-app01-prod.tfvars
cluster-app02-dev.tfvars
cluster-app02-prod.tfvars
/modules
/asg_scaling_policy
variables.tf
main.tf
outputs.tf
/s3_bucket
variables.tf
main.tf
outputs.tf
/iam_policies
firehose-role-policy.json
firehose-role.json
/templates
userdata.tpl
variables.tf
main.tf
outputs.tf
Jenkinsfile
atlantis.yaml
Q) How do you run terraform? Atalntis:
Links:
Atlantis
Q) What is Atlantis?
Atlantis is an application for automating Terraform via pull requests. It is deployed as a standalone application into your infrastructure. No third-party has access to your credentials.
Q) How Atlantis works?

Q) How is Atlantis integrated with git repo?
Atlantis listens for GitHub, GitLab or Bitbucket webhooks about Terraform pull requests. It then runs terraform plan and comments with the output back on the pull request.
When you want to apply, comment Atlantis apply on the pull request and Atlantis will run terraform apply and comment back with the output.
Q) What Atlantis commands are used to run Terraform?
#default
atlantis plan -w {workspacename}
#custom options
atlantis plan -w {workspacename} -var-file=.env/{workspacename}.tfvars
atlantis apply -w {workspacename}
atlantis plan -w {workspacename} -var-file=.env/{workspacename}.tfvars
Note: For Atlantis to be able to plan automatically with .tfvars files, you need to create an atlantis.yaml file to tell it to use -var-file={YOUR_FILE}.
Q) How do you create infrastructure using atlantis?
- Git repo: Create a new file in the folder that holds tfvars for each workspace; that creates a pull request as well
- Git repo: Type atlantis plan command in the comment section for the pull request
- Git repo: Check the output from atlantis and if output is good
- Git repo: Type atlantis apply command in the comment section for the pull request
- Git repo: merge pull request.
Q) How Atlantis executes terraform commands?
- clones repo
- intializes terraform
- creates a workspace and selects the workspace
- plans using the {workspace}.vars file
Q) What is atlantis.yaml?
An atlantis.yaml file specified at the root of a Terraform repo allows you to instruct Atlantis on the structure of your repo and set custom workflows.
atlantis.yaml files are only required if you wish to customize some aspect of Atlantis. The default Atlantis config works for many users without changes.
Example use cases for customizing
- Run a custom script after every apply
- Adding extra arguments to Terraform commands
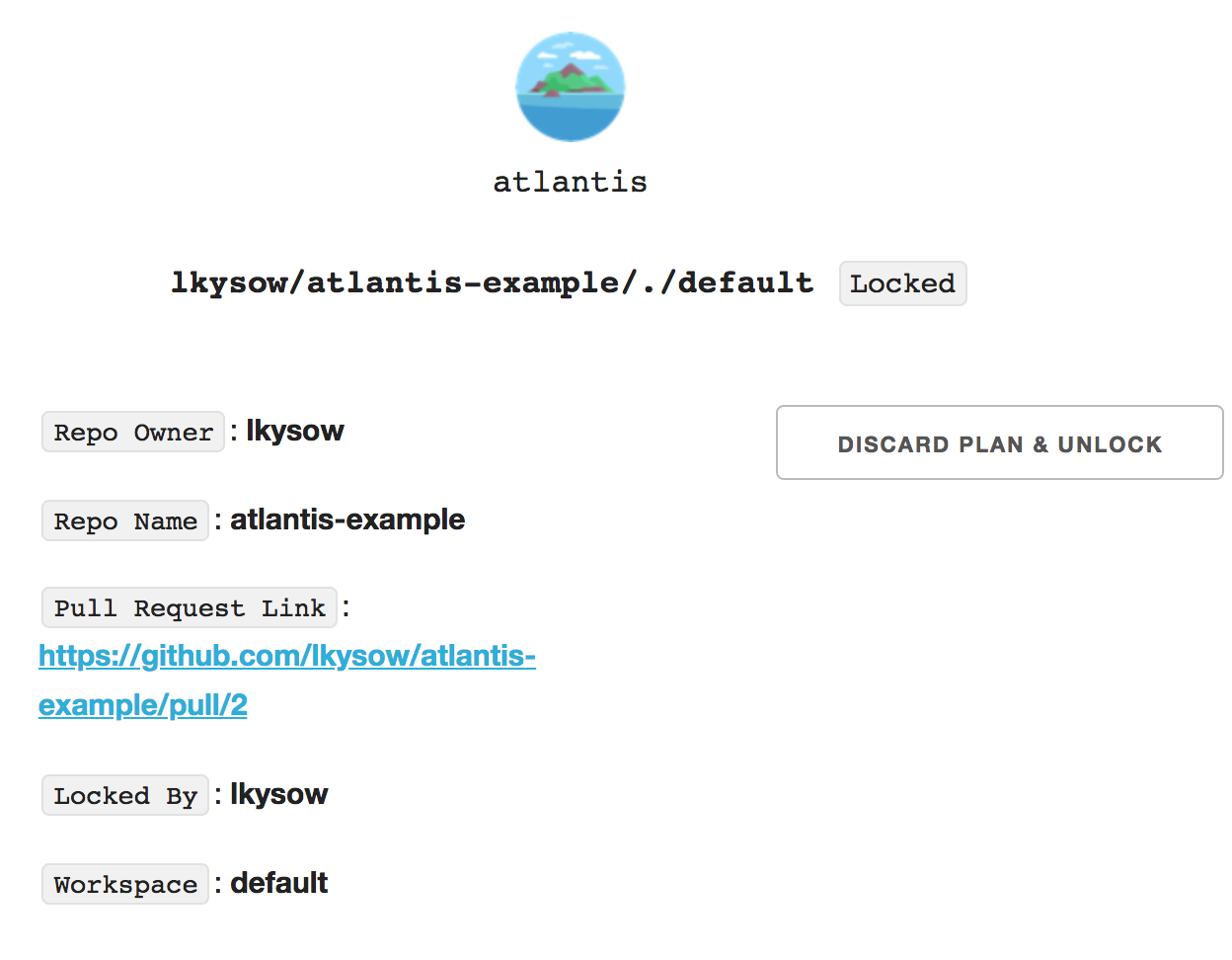
Q) What is Atlantis locking?
When a plan is run, the directory and Terraform workspace are Locked until the pull request is merged or closed, or the plan is manually deleted.

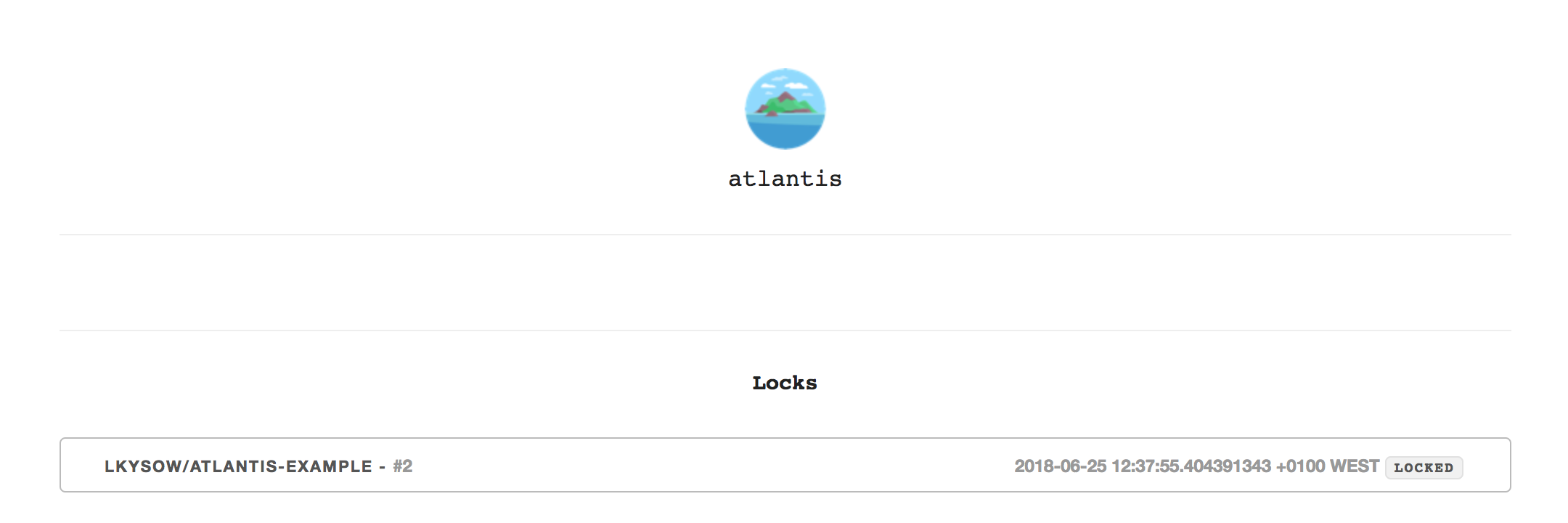
Q) Where can I see the locks?
To view locks, go to the URL that Atlantis is hosted at